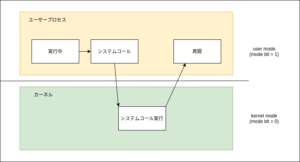
今回は、CPUの仮想化を理解する上での2つの観点のうち、2つ目の「複数あるプロセスの中でどれを優先すべきか?」、というポリシー(方針)の話をしようと思う。
ここで、良いスケジューラを実装するために重要なこととして、パフォーマンスの他に公平性(Fairness)も挙げられることに注意する。
まず、前提としてシステム上で作られるプロセスは一様でないことを考えよう。そのプロセスがCPUバウンドなのかI/Oバウンドなのか、そのプロセス実行にかかる時間はどれくらいなのか、など多種多様なプロセスが作られる。それらのプロセスを、効率的にかつ公平性を保ったまま実行していくには複雑なルールが必要となる。
主流となっているスケジューリングポリシーの二つを紹介する。
1.Multilevel Feedback Queue(MLFQ)
この手法は、Solaris、Windows、MacOSで採用されている。
このポリシーは、以下のルールに沿って複数プロセスにCPUの時間を割り振っていく。
- プロセスはそのプロセスの持つ優先度(後述)の高いものから実行されていく。
- もしも同じ優先度を持つプロセスがあった場合、ラウンドロビン式(A –> B –> C –> A –> B –> C –>…)に実行される。
- プロセスが生成されたとき、最も高い優先度が与えられる。
- 優先度ごとに決められた時間を使い切ったプロセスは(連続、断続的に関わらず)、優先度を下げられる。
- 一定の時間が経つと、すべてのプロセスに最も高い優先度を与える。
一つ一つルールを追って、なぜそのルールが必要なのかを考えていこう。
ルール1:プロセスはそのプロセスの持つ優先度(後述)の高いものから実行されていく
たくさんあるプロセスの中から、それぞれのCPU実行時間をコントロールできるよう、優先度(Priority)という値を導入する。
ルール2:同じ優先度を持つプロセスは、ラウンドロビン式に実行される。
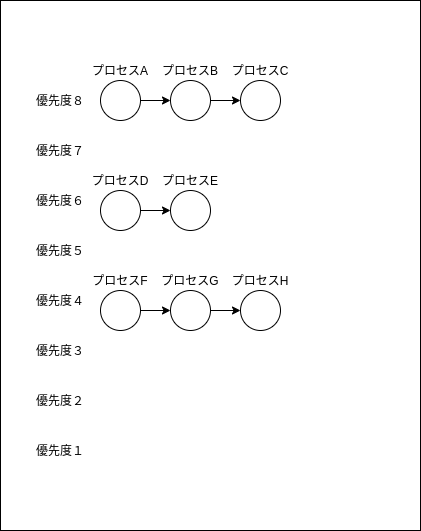
MLFQでは、優先度という概念とともに、キューというデータ構造を採用し、同じ優先度にあるプロセスは同じキューに格納される。(下図参照)

ルール3:すべてのプロセスは生成時、最も高い優先度を持つ
すべてのプロセスは作られた後、最も高い優先度のキューに追加される。このルールによって、生成直後のプロセスに直ぐにCPUが回ってくるようになる。
このルールは次のルールとセットで考えるとわかりやすいだろう。
ルール4:優先度ごとに決められた時間を使い切ったプロセスは(連続、断続的に関わらず)、優先度を下げられる
生成後、最も高い優先度のキューに追加されたプロセスは、その実行時間が各優先度のキューに設定された時間(タイムスライス)を超えたとき、1つ下の優先度のキューに移動される。このルールによって、CPUを頻繁に使うようなプロセスは、優先度を下げられることで、他のプロセスにCPU時間が回るよう、公平性を維持できる。
ここで、連続的にCPU時間を使いすぎるCPUバウンドなプロセスはおいといて、I/Oバウンドなプロセスのような、断続的にCPU時間を使い、他のプロセスに頻繁にCPUを回すプロセスまでもが、優先度をさげられる仕様にしているか考えよう。これは、決められた時間を使い切る前に他のプロセスにCPU時間を回して、優先度を高いままにしようとする悪意のあるプロセスを防ぐためである。
ルール5:一定時間が経つと、すべてのプロセスは優先度を最大に設定される
これはPriority Boostと呼ばれ、ルール4までのポリシーでは対応できない以下のようなケースに応じるために導入される。
- I/Oバウンドなプロセスが多くなってくると、それらはCPUバウンドなプロセスに比べ優先度を維持する傾向があるため、CPUバウンドなプロセスにいつまでもCPU時間が回ってこない。
- 今までCPUバウンドだったプロセスが、I/Oバウンドなプロセスになることがある。
このようにしてMLFQは実装されるが、考えなければいけないことがもう一つある。それは、MLFQ実装に必要なパラメータである。
- キューの数(優先度の数)
- キュー毎の時間(タイムスライス)
- Priority Boostまでの時間
これらの値は実験を通して最適値を見つけるか、OS管理者に設定インターフェースを与えるのが手であるが、タイムスライスに関しては、高い優先度のキューほど小さい値を設定したほうがいいだろう。
Completely Fair Schduler(CFS)
CFSはLinuxで使われているポリシーだ。
スケジューリングにおいて重要なことは公平性とそのパフォーマンスである。Linuxで採用されているCFSでは、その2つのゴールをデータ構造とその設計を巧みに用いて達成している。
CFSの重要な要素として、
- Virtual Runtime (vruntime)
- Weighting (Niceness)
- Red Black Tree
が挙げられる。ひとつひとつ見ていこう。
1.Virtual Runtime(vruntime)
稼働しているプロセスは、それぞれvruntimeという値を持っていて、そのプロセスが実行された時間がどんどん蓄積されていく。スケジューラはcontext switchの際に、最も低いvruntimeを持つプロセスをスケジュールする。
vruntimeと共に導入されるパラメータとして、sched_latencyがある。この値を現在のプロセス数で割ったものが、タイムスライスとしてそれぞれのプロセスの実行時間として許される。これは48ミリ秒に設定されることが多い。例として、現在4つのプロセスが稼働中だとすると、それぞれのプロセスの一回の実行時間(Context Switchまでの時間)は48 / 4 = 12ミリ秒となる。
一見上手く行きそうなアプローチであるが、プロセス数が多くなったときに起こる問題が一つある。プロセス数が多くなると1つのプロセスに許される実行時間に対して、スイッチ回数が相対的に多くなる、つまりスケジューラそのもののオーバーヘッドが相対的に大きくなってしまうのである。
そこで、この問題を解決すべく、min_granularityというパラメータが用意される。これは、タイムスライスの最小値であり、6ミリ秒であることが多い。例として、sched_latency = 48ms、min_granularity = 6msの環境を考えてみると、プロセス数が8を超えたときにタイムスライスは6ミリ秒を下回ることがなくなる。
2.Weighting (Niceness)
LinuxのCFSでは、vruntimeの他に、管理者が複数プロセスの中で優先度をコントロールできるよう、NicenessというUnixで生まれた概念を採用している。プロセスはそれぞれniceという-20から19の値を取るパラメータを持ち、注意すべきは、この値が高いほど優先度が低い。
この-20から19までの40種類の値にそれぞれweightという定数が割り当てられていて(下図)、これらの値はタイムスライスとvruntimeを計算するのに使われる。

あるプロセスに割り当てられるCPU時間は、決められたweight配列の値とsched_latencyの値を用いて以下のように計算される。

例として、sched_latency = 48msの環境で、2つのプロセスA、Bが稼働中であり、それぞれのniceが-5と0であると仮定しよう。上のweight配列を参考にして、それぞれのプロセスに割り当てられるCPU時間を計算すると、
time_slice(A) = 3121 / (3121 + 1024) x 48 = 36.15 ms
time_slice(B) = 1024 / (3121 + 1024) x 48 = 11.86 ms
となる。
Weightはvruntimeの計算にも用いられ、以下の式を用いてvruntimeは更新される。

runtimeという実際の実行時間に、そのプロセスとnice=0のプロセスのweightの比率をかけたものがvruntimeに蓄積される。
3.Red Black Tree
スケジューラのパフォーマンスを上げる方法として、「次に実行するプロセスを決定する」過程にかかる時間を極力短くする、ということが挙げられる。システム上で可動するプロセス数は1000を超えることが現代のOSでは普通であり、それらの中から次に実行するプロセスを効率的に探し出すのには、プロセス数が多少増えても検索時間に影響を及ぼさないデータ構造を採用することが大事である。
そこで、CFSはRed Black Treeをプロセス情報を保存するデータ構造に採用している。注意することとして、すべてのプロセスがそこに格納されるわけではなく、稼働中のプロセス、Readyなプロセスのみが格納され、I/O処理やネットワーク処理を待っているプロセスは他で管理される。
Red Black Treeでは、挿入、削除にかかる時間は要素数に対して対数的に増えるため、線形的に増えるリストよりも適したデータ構造であると言える。
また、気をつけるべき仕様として、それまでI/O処理などを待っていて眠っていたプロセスが、I/Oを終えてReadyなプロセスとしてツリーに追加されるとき、そのvruntimeはツリー内の最小vruntimeへと更新される。この挙動は、I/O処理に10秒間かかったと仮定するとわかりやすい。もしもvruntimeをこのように更新しなければ、そのプロセスは次の10秒間CPUを独占することになるからだ。